
7.28 MST-GAT: A multimodal spatial–temporal graph attention network for time series anomaly detection
显示效果更优: https://www.craft.me/s/FEfkjT8GWFVY5E
不知道为什么公式渲染不出来我真是醉了
Source: Information Fusion
一些缩写:
MTS: multimodal time series
动机
- 单一的单变量时间序列无法反应实体的整体状态,简单地将多个单变量时间序列的检测结果结合起来的方法往往表现不佳
- 【数据和特征捕获方面的问题】以往的MTS方法考虑了时间依赖性,能捕获到时间维度上的动态变化,但是忽略了不同时间序列之间的空间依赖性,尽管有些改进,但是仍没能显式地捕捉多模态时间序列之间的多模态相关性
- 预测的可解释性问题(8.15 Towards Graph-level Anomaly Detection via Deep Evolutionary Mapping 这篇文章也提到了该问题)也许异常的检测结果的可解释性问题很重要
用了什么网络
- multimodal 用于明确捕捉多模态时间序列之间的模态依赖关系和空间依赖关系:
- 一个多头注意力模块 multi-head attention module
- 两个关系注意力模块 relational attention module
- intra-modal attention 内部modal
- inter-modal attention 外部modal
- 时序卷积网络 temporal convolutional network,用于捕获每个时间序列中的时间依赖关系 temporal dependency
其他模块
- 重构模块:用于重构输入数据。它帮助网络学习对原始数据进行重构,以保留重要信息和特征,有助于提高整体的数据表征能力。
- 预测模块:用于预测下一个时间戳的特征。通过预测未来的特征,网络可以理解数据的演进趋势和可能出现的异常情况。
MST-GAT方法概览
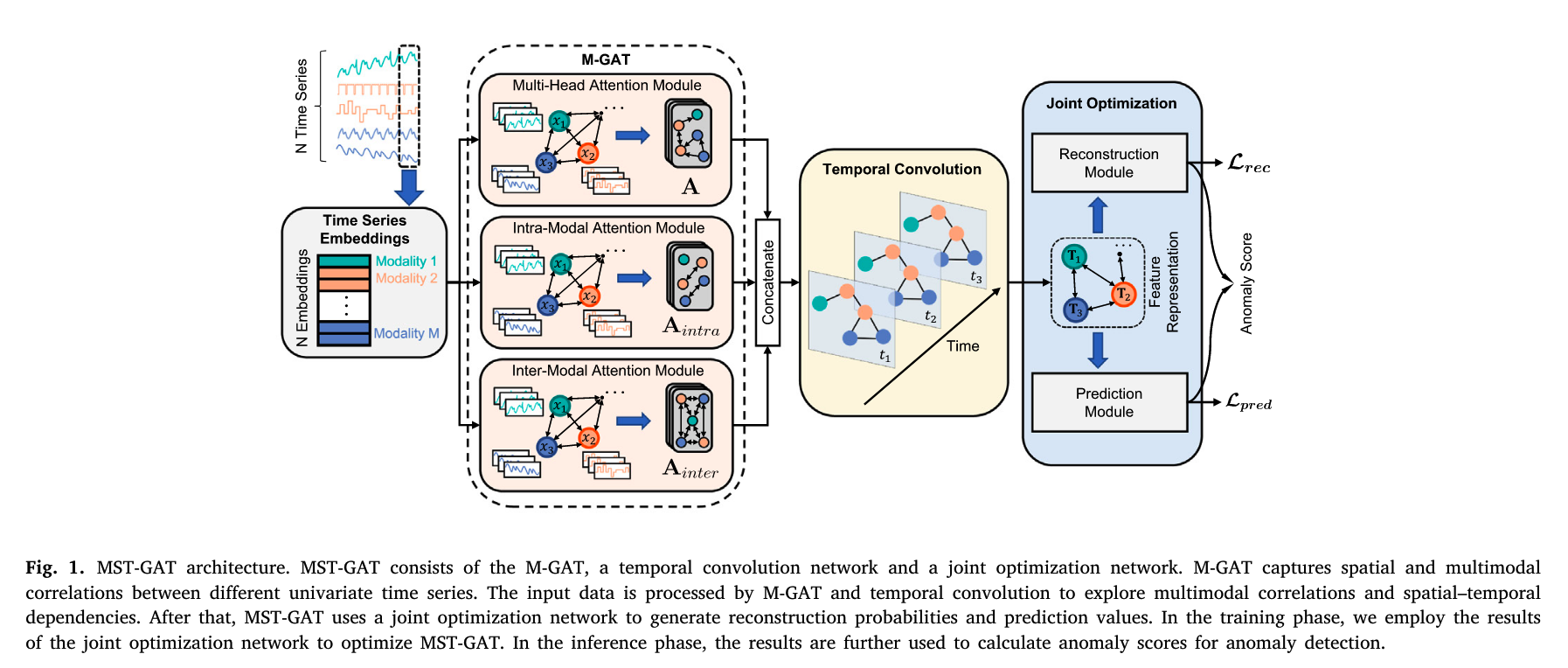
- 网络结构学习 Graph structrue learning
“to learn a graph structure in the spatial dimension” - Multimodal Graph Attention Network (M-GAT) 它包含三个注意力模块
- 多头注意力
- 两个关系注意力
- 时序卷积网络
- 联合优化
“optimizes both reconstruction and prediction targets”
方法细节
- 数据格式&问题定义(有公式,见notability)
- 问题定义: X \rightarrow y ,y是序列,有 T^\prime 个元素,每个元素都是1/0,表示有无异常
- 图结构学习:
- 面向的是time series,先认为初始的embedding v_i 是已经通过默写方法获得了,接下来的首要目标是通过这些向量构造出一个图网络
- 衡量节点相似度(cosine similarity),对每个节点选出top k个最大相似度的节点,然后构造矩阵A(节点j在节点i的top k里面,则A_{ij} = 1 ,否则=0)。于是邻接矩阵A能够北构造出,进而有了图网络
- 空间维度?滑动窗口,每次从X中观测w个x
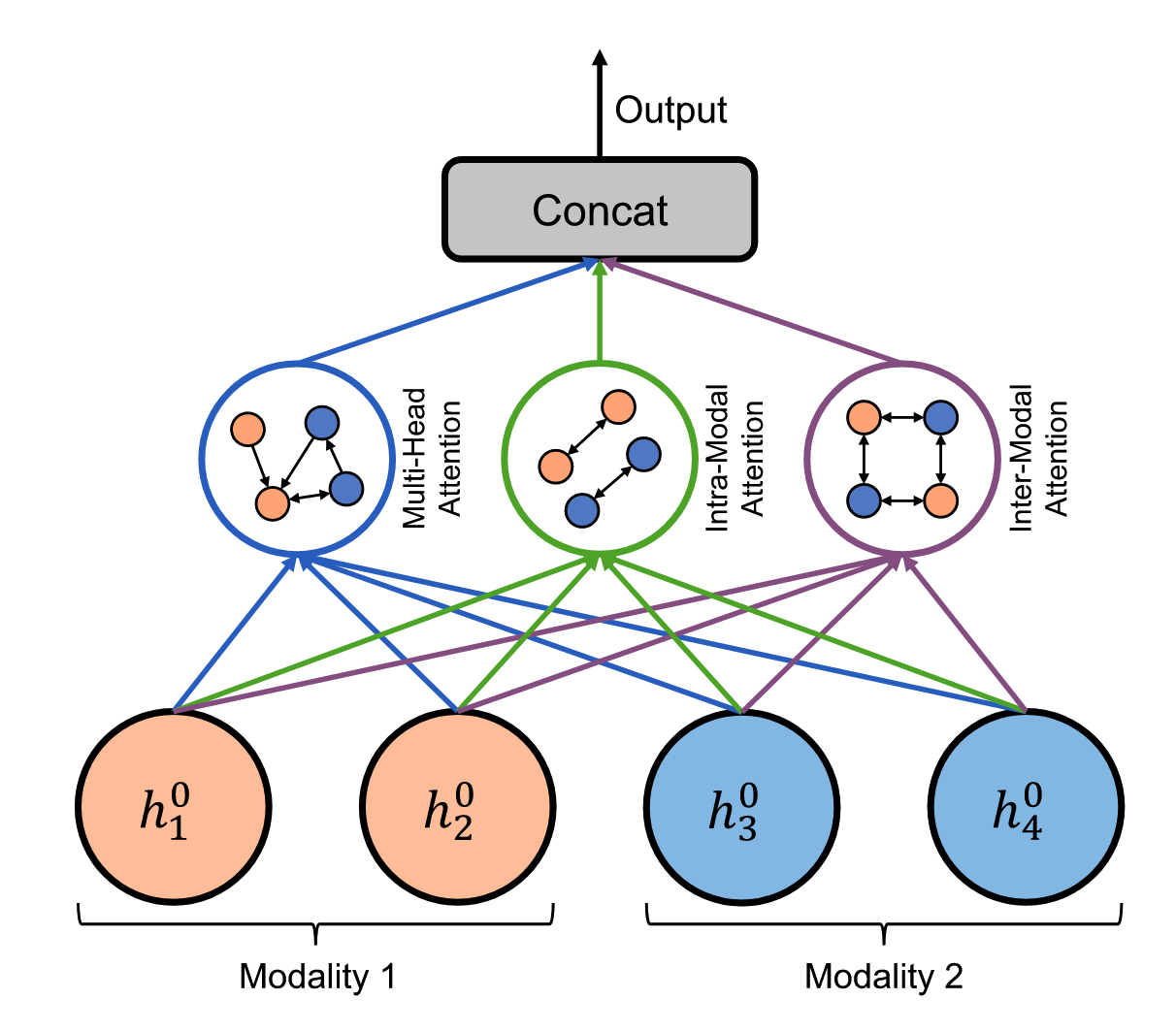
对于训练时间序列X,使用长度为w的滑动窗口在每个时刻产生一个固定长度的输入。定义 X为t时刻M-GAT的输入
M-GAT由三个注意模块组成,即多头注意、通道内注意和通道间注意。多头注意力模块侧重于建模多模态时间序列之间模态无关的空间关系,而模态内和模态间注意力模块侧重于捕捉不同时间序列之间的多模态相关性。 - 时序维度卷积。多模态图注意力在空间维度上捕获每个节点的邻居信息,而时间卷积网络在时间维度上应用立场卷积来捕获时间动态。
- 联合优化:两个任务:reconstruction和prediction,loss函数包含两部分优化目标
\mathcal{L}=\gamma_1 \mathcal{L}_{\text {rec }}+\left(1-\gamma_1\right) \times \mathcal{L}_{\text {pred }}
前面那个loss是reconstruction的,后面的是prediction模块的- reconstruction module:该模块的目标是学习输入数据的重构概率,使用VAE (Variational autoencoder) 去重构图网络,给定输X_t,VAE用条件概率p_\psi(\mathcal{X}_t|z_t)来重构X,z是representation。训练重构模块的目标是最大化zt的后验分布:
p_\psi(z_t|\mathcal{X}_t)=p_\psi(\mathcal{X}_t|z_t)p_\psi(z_t)/p_\psi(\mathcal{X}_t)
最后一项可以给出形式化定义但是很难计算,所以用另一个模型去近似它,最后,修改后的重构损失为:
\begin{aligned}\mathcal{L}_{rec}&=-\mathrm{E}_{q_\rho(z_t|\mathcal{X}_t)}[logp_\psi(\mathcal{X}_t|z_t)]\\&+D_{KL}(q_\rho(z_t|\mathcal{X}_t)\parallel p_\psi(z_t))\end{aligned} - prediction module:用MLP作为时序卷积后的预测网络
\mathcal{L}_{pred}=\frac1{T-w}\sqrt{\sum_{i=1}^N(x_{i,t+1}-\hat{x}_{i,t+1})^2} - 异常打分、推断:上面两个模块分别生成重构概率p_i和预测\hat{\bf{x}}_{i},每个时间戳的最终异常分数是每个时间序列的异常分数之和
\mathrm{score}=\sum_{i=1}^N\frac{(1-p_i)+\gamma_2\times(\mathbf{x}_i-\hat{\mathbf{x}}_i)^2}{1+\gamma_2}
推断阶段对评分通过设定阈值的方法判断每个时间步上是异常或非异常,阈值如何选定——peaks-over-threshold (POT)算法

- reconstruction module:该模块的目标是学习输入数据的重构概率,使用VAE (Variational autoencoder) 去重构图网络,给定输X_t,VAE用条件概率p_\psi(\mathcal{X}_t|z_t)来重构X,z是representation。训练重构模块的目标是最大化zt的后验分布:
实验
数据集
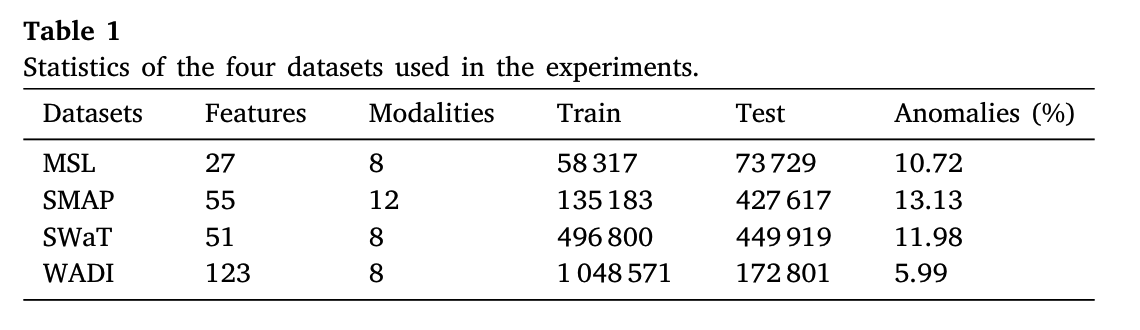
前两个数据集的论文:Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding
这些数据集也不是常见的社交网络数据集,而是从什么传感器上采集到的
baselines
单模块的
PCA: Principal component analysis
AE: Autoencoder
DAGMM: Deep autoencoding Gaussian model
LSTM-VAE: LSTM-VAE substitutes the fully connected network in variational autoencoder with LSTM
多模块的
MAD-GAN: Multivariate anomaly detection
OmniAnomaly: OmniAnomaly
USAD: Unsupervised anomaly detection
GDN: Graph deviation network
评价指标
标准的P、R、F1
感悟
- 本文的研究对象本身虽然不是图,但是它最后检测出来的东西依然是图级别的
- 并非要能够直接建模成图网络的东西才能够用图异常检测技术。如果能够通过某些方式获得样本的向量,通过很多方法如相似度计算,就能够人为的构造出一个网络,基于这个网络就能够做异常检测的许多工作,包括节点、边、图等等